· on this page
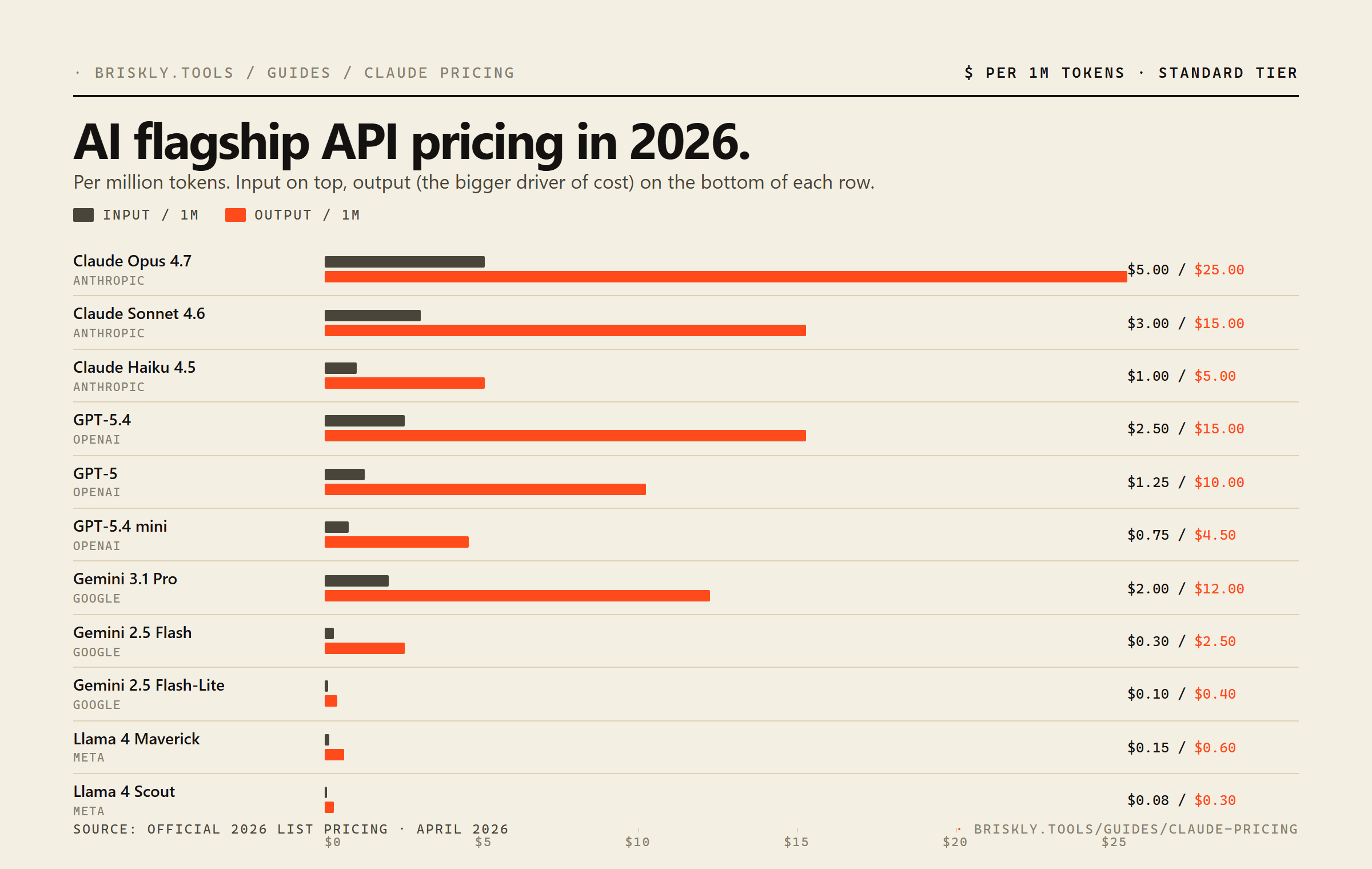
Claude's pricing quietly shifted in early 2026. Opus 4.7 dropped from $15 / $75 per million tokens to $5 / $25, a 67% cut on input and a 67% cut on output, without a corresponding quality drop. That one change reset the cost-per-intelligence frontier. Then on April 23, 2026 OpenAI shipped GPT-5.5 at $5 / $30, the first fully retrained base model since GPT-4.5, agentic-focused, matching Opus on input and surpassing it on output. GPT-5.4 dropped to mid-tier at $2.50 / $15. Gemini 3.1 Pro stays at $2 / $12, and Llama 4 Scout still anchors the cheap end at $0.08 / $0.30.
Here's what Claude costs right now, how it compares against every serious alternative, and, more usefully, when each model actually wins on real workloads.
Claude API pricing (April 2026)
| Model | Input / 1M | Output / 1M | Context |
|---|---|---|---|
| Claude Opus 4.7 | $5.00 | $25.00 | 1M |
| Claude Sonnet 4.6 | $3.00 | $15.00 | 200K |
| Claude Haiku 4.5 | $1.00 | $5.00 | 200K |
Source: claude.com/pricing. Prices shown are standard tier (no batch discount, no cache). Updated April 21, 2026.
The important shift: Opus is no longer a "reserve this for the hardest tasks" model from a pricing standpoint. At $5 / $25 it sits exactly at GPT-5.5's input price and $5 below its output price. The main reason to skip Opus now is latency (it's slower than Sonnet) or throughput (Anthropic rate-limits the top tier more aggressively during peak hours).
Claude vs. GPT-5, Gemini, and Llama, the full board
| Model | In | Out | Ctx |
|---|---|---|---|
Claude Opus 4.7 Anthropic | $5.00 | $25.00 | 1M |
Claude Sonnet 4.6 Anthropic | $3.00 | $15.00 | 200K |
Claude Haiku 4.5 Anthropic | $1.00 | $5.00 | 200K |
GPT-5.5 OpenAI | $5.00 | $30.00 | 272K |
GPT-5.5 Pro OpenAI | $30.00 | $180.00 | 1.05M |
GPT-5.4 OpenAI | $2.50 | $15.00 | 272K |
GPT-5.4 mini OpenAI | $0.75 | $4.50 | 272K |
GPT-5 OpenAI | $1.25 | $10.00 | 400K |
Gemini 3.1 Pro Google | $2.00 | $12.00 | 1M |
Gemini 2.5 Flash Google | $0.30 | $2.50 | 1M |
Gemini 2.5 Flash-Lite Google | $0.10 | $0.40 | 1M |
Llama 4 Maverick Meta | $0.15 | $0.60 | 1M |
Llama 4 Scout Meta | $0.08 | $0.30 | 10M native (1M hosted) |
Prices per 1M tokens USD, standard tier. Llama prices are hosted rates on Fireworks / DeepInfra. Use the LLM token counter to run real numbers on your own prompt across all 21 models at once.
When Claude actually wins on cost
Per-token pricing is necessary but not sufficient. The better question is cost per successful task. Three patterns where Claude is actually the cheaper choice despite higher headline rates:
- Complex agentic loops. Opus 4.7's tool-use reliability, picking the right tool, parsing structured output, recovering from errors, is measurably better than any current competitor on third-party benchmarks. For a 5-step agent that a cheaper model would fail on turn 3 and retry, the all-in cost (including retries and error-recovery tokens) often favors Opus.
- Writing that needs to ship. For customer-facing copy, longform content, or anything a human will read critically, Sonnet 4.6 produces text that needs less editing than Gemini 3 Flash or GPT-5 mini. Cheaper per token doesn't save money if you're spending a human's time fixing it.
- Prompt caching on long system prompts. Claude's 5-minute cache TTL and 90% cached-input discount is competitive with OpenAI. If you have a 10K-token system prompt you're reusing across thousands of calls, caching takes effective Sonnet input pricing from $3 to ~$0.30 per 1M, suddenly cheaper than uncached Gemini 3.1 Pro.
When it's cheaper to leave Claude
- High-volume classification / extraction. If you're running 100K+ classifications a day on short inputs, Gemini 2.5 Flash-Lite at $0.10 / $0.40 or Llama 4 Scout at $0.08 / $0.30 is 10× cheaper than Haiku and the quality gap is usually invisible for these tasks.
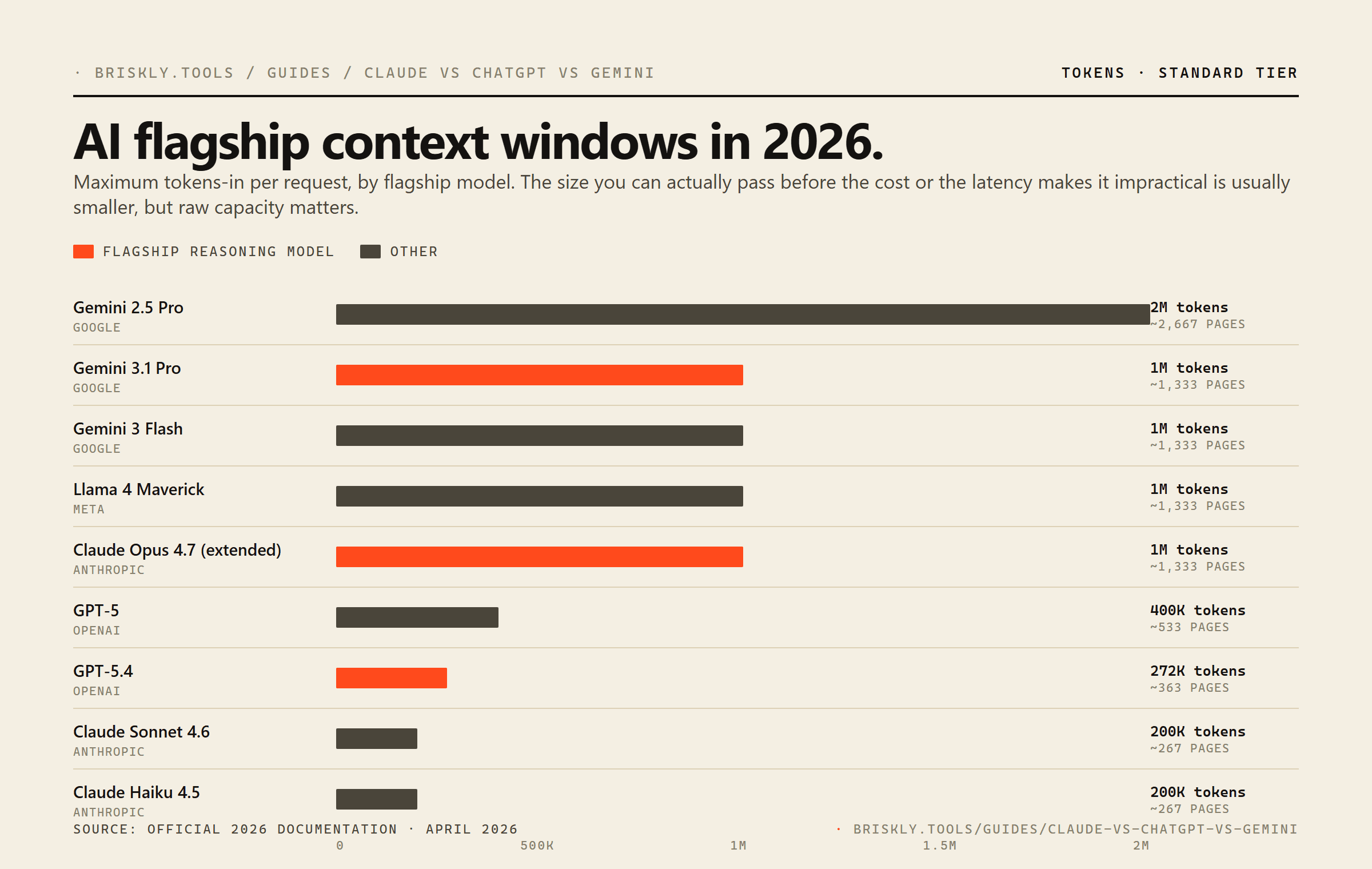
- Long-context summarization. Gemini 2.5 Pro gives you 2M context at $1.25 / $10. Claude Opus's extended 1M context costs you the full $5 / $25. For ingesting entire codebases, legal corpora, or long video transcripts, Gemini's cost-per-context ratio wins by a wide margin.
- Ultra-budget workloads. Open-weight Llama 4 on DeepInfra at $0.08 / $0.30 is hard to beat if you don't need Anthropic's safety layer, Claude's writing voice, or commercial SLA. For internal tooling, one-off batch jobs, or research, it's almost always the right cost answer.
- Tasks with heavy visual / audio input. Gemini is cheaper on multimodal input across the board and handles video natively. Claude can take images but charges token-equivalent for them; for video-heavy workloads Gemini usually wins the cost fight outright.
Real examples
Three concrete workloads with actual per-request costs, so the numbers are less abstract:
Example 1, 10K customer-support chatbot requests / day
Average 800 input tokens (system + conversation history) and 200 output tokens per turn.
- · Claude Haiku 4.5: ~$18 / day
- · GPT-5 mini: ~$6 / day
- · Gemini 2.5 Flash: ~$7.40 / day
- · Llama 4 Scout: ~$1.60 / day
For this workload, short exchanges, conversational tone, moderate reasoning, any of these will do the job. Llama 4 Scout is 11× cheaper than Haiku. If your quality bar justifies the gap, Haiku's more reliable voice might still be worth it; if not, it's an easy switch.
Example 2. RAG over a 50K-token knowledge base, 5K queries / month
Average 4K tokens retrieved per query plus a 500-token query, 600-token answer.
- · Claude Sonnet 4.6 (with cache): ~$10 / month
- · GPT-5.4: ~$90 / month
- · Gemini 3.1 Pro: ~$81 / month
- · Gemini 2.5 Flash: ~$14 / month
Caching tips this strongly toward Sonnet, the 4K context per query is mostly cacheable. Without caching, Gemini 2.5 Flash is the pragmatic answer at 1.4× Claude-cached price with no caching complexity.
Example 3. Code generation agent, 500 sessions / month
Multi-turn agentic session averaging 20K input + 4K output tokens across tool calls.
- · Claude Opus 4.7: ~$100 / month
- · GPT-5.4: ~$55 / month
- · Gemini 3.1 Pro: ~$44 / month
- · Claude Sonnet 4.6: ~$60 / month (but higher retry rate)
Opus is the most expensive here, but on agentic coding tasks it's the only model in the set with a >80% session-success rate on third-party evals. Cheaper models can save you ~$50/mo and cost you 10 hours of debugging failed sessions, easy math.
Discounts that actually matter
- Prompt caching, up to 90% off cached input tokens on Claude and OpenAI, 75% on Gemini. If you have a 5K+ token system prompt reused across calls, this is the single biggest saving available to you. Worth the integration work within one day of volume.
- Batch APIs, 50% off both input and output on Claude Batch and OpenAI Batch for 24-hour-latency-tolerant workloads. For overnight content processing, backfill jobs, or bulk categorization, it's effectively halving your bill.
- Commit discounts. Anthropic, OpenAI, and Google all offer annual commit discounts in the 10-30% range above roughly $100K/year spend. Not useful at low volume; very useful at scale.
- Free tiers. Gemini still has a generous free tier (limited RPM, but real). Useful for development and for side projects; not a production strategy.
FAQ
How much does Claude cost per 1M tokens?
As of April 2026: Claude Opus 4.7 is $5 input / $25 output per 1M tokens, Claude Sonnet 4.6 is $3 / $15, and Claude Haiku 4.5 is $1 / $5. Opus dropped significantly from its earlier $15 / $75 list price, the most important pricing change in the Claude line this year. All three sit on the same 200K context window for standard use; Opus 4.7 additionally supports a 1M-token extended context mode.
Is Claude cheaper than GPT-5.5?
At the new flagship tier (April 2026), Claude Opus 4.7 at $5 / $25 is exactly the same on input as GPT-5.5 ($5 / $30) and $5 cheaper on output. For typical balanced workloads, Opus runs ~15% cheaper than GPT-5.5. The previous flagship GPT-5.4 (now mid-tier at $2.50 / $15) is still cheaper than Opus on input but more expensive on output, so for chat-style workloads GPT-5.4 wins on cost. At the low-tier, Claude Haiku 4.5 ($1 / $5) is pricier than GPT-5 mini ($0.25 / $2) but cheaper than GPT-5.4 mini ($0.75 / $4.50). Cheapest per-token isn't always cheapest per-task, model quality affects how many retries or how much post-processing you need.
What is the cheapest Claude model?
Claude Haiku 4.5 at $1 input / $5 output per 1M tokens. It has the same 200K context window as Sonnet, sacrifices quality on complex reasoning tasks, and runs about 3× faster than Opus. For high-volume, low-complexity workloads (classification, entity extraction, simple transformations) Haiku is usually the right pick in the Claude family.
Is Claude Opus 4.7 worth the premium?
It depends on what you're doing. For one-shot hard reasoning tasks, agentic code generation, nuanced legal analysis, complex tool-use chains. Opus still holds its edge over cheaper models and the extra cost often pays for itself by reducing retries or post-hoc correction. For summarization, extraction, Q&A over documents, and routine code completion, Sonnet 4.6 produces results most users can't distinguish from Opus at a fraction of the cost. Opus is also the only Claude with the 1M-token extended context mode.
How does Claude pricing compare to Gemini?
Gemini is generally cheaper per token than Claude, especially at the Flash tier. Gemini 2.5 Flash at $0.30 / $2.50 is roughly 3× cheaper than Claude Haiku. Gemini 3.1 Pro at $2 / $12 undercuts Claude Sonnet 4.6. Where Claude wins: for pure writing quality, code generation, and tool-use reliability, Claude still has a measurable edge in most third-party evaluations. Gemini wins on raw throughput, multimodal work, and the 1M to 2M context windows on the Pro tier.
What's the cheapest LLM API right now?
For open-weight deployments on hosted providers: Llama 4 Scout at $0.08 input / $0.30 output per 1M tokens (DeepInfra) is the cheapest among current-gen capable models. Llama 4 Maverick at $0.15 / $0.60 (Fireworks) is slightly pricier but more capable. Among closed-weight flagships, Gemini 2.5 Flash-Lite at $0.10 / $0.40 is the cheapest. GPT-5.4 nano at $0.20 / $1.25 is the cheapest recent OpenAI model. Absolute cheapest doesn't mean best value, match to the task.
How do I actually calculate my API cost?
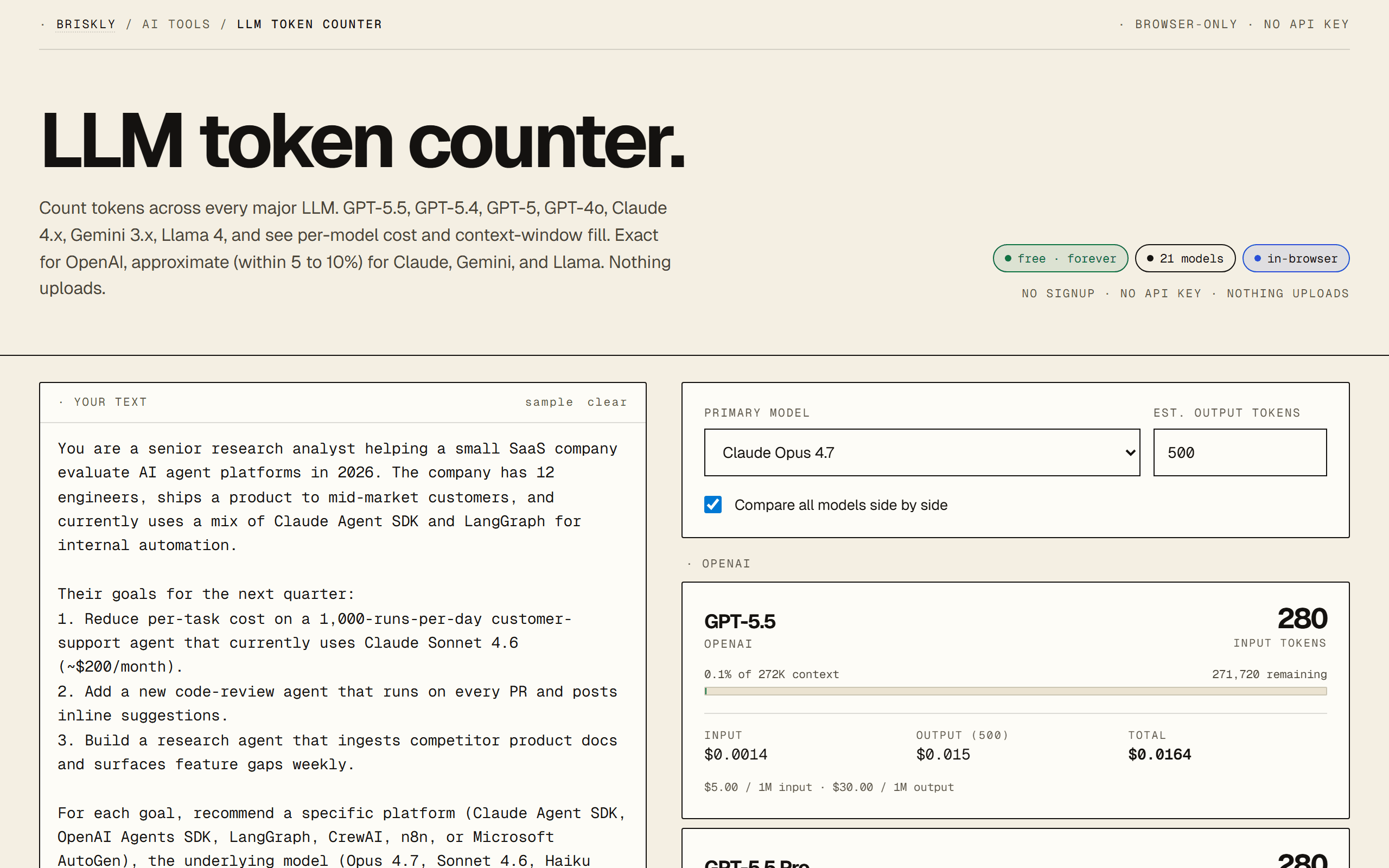
Three numbers: your average input tokens per request, your average output tokens per request, and your request volume. Multiply input by the input rate, output by the output rate, sum, and multiply by volume. Most developers underestimate output tokens, because AI replies tend to be verbose by default. Our free LLM token counter runs the math for you on a single prompt across all 21 major models, paste once, see exact per-model cost.
Does cached / prompt-caching pricing change things?
Significantly, if you can structure for it. Claude offers prompt caching at up to 90% discount on cached input tokens (after a 2.25× write-cost hit). OpenAI offers up to 90% discount on cached input with no write penalty. Gemini offers up to 75%. If you have a long system prompt + changing user prompts, caching can easily cut your bill by 60-80%. Batch APIs (Claude Batch, OpenAI Batch) offer roughly 50% off both input and output for 24-hour-latency-tolerant workloads.
Which model should I pick if cost is the only factor?
Llama 4 Scout on DeepInfra for pure volume. If you need a closed-weight with guaranteed uptime, Gemini 2.5 Flash-Lite. If you need the best cost-to-quality on reasoning tasks specifically, Claude Haiku 4.5. If you need massive context cheaply, Gemini 2.5 Flash (1M context at $0.30 / $2.50). Cost-only is rarely the right framing, the better question is cost per successful completion, which requires running your own evals.
Related
- · LLM token counter, run the math on your own prompt across all 21 models at once. Paste once, see exact per-model cost.
- · Prompt caching explained, the math behind the 60-80% cost cuts above.
- · Claude vs ChatGPT vs Gemini, the broader head-to-head, beyond pricing.
- · MCP server primer, how to plug external tools into Claude Desktop and Cursor.